Hi! I’m Emily Somach, a graduate student at University of Maryland’s College of Information Studies. I am working towards my Master of Library Science degree, specializing in Archives, Records, and Information Management, and work as a Graduate Assistant in the UMBC Special Collections.
For the past six months, I have been working on an exciting project to create Encoded Archival Description (EAD) for Special Collections’ archives. The project is funded by the National Historical Publications & Records Commission (NHPRC) through the grant opportunity entitled “Documenting Democracy: Access to Historical Records Projects.”
What is EAD?
Well, the short answer is that EAD is a standard; it is used to encode data and information about personal papers or corporate records (i.e. archival materials). EAD is also an XML schema called EAD-XML, which means that an EAD record is written using the markup language XML (which is very similar in structure to the more familiar HTML). Lastly, an EAD record is also a type of finding aid.
And what, you may ask, is a finding aid? A finding aid is the archival term for an index or guide to a collection. It is useful to both archivists and researchers; it helps the former gain intellectual and physical control over collections, and allows the latter to find and use materials relevant to their work.
Essentially, EAD allows archivists to create platform independent records (or finding aids, the two are synonymous when discussing EAD) that are more dynamic and versatile than a word document or content management system record. EAD finding aids are easy to represent online and share between systems; they allow the public to find and access information about archival collections through online catalogs or discovery tools. Ultimately, collections represented in EAD become far more accessible and easy to locate and use.
How to Create EAD
EAD can be created by hand or through automated processes, but manually creating an entire record from scratch in XML is very time consuming and cumbersome. Luckily, for this project, we did not have to start from scratch or do everything by hand. Instead, we opted to repurpose the data we already had in PastPerfect, the content management system used by Special Collections. We developed a workflow that allows us to extract this data from PastPerfect and convert it into EAD-XML. While some post-processing and manual edits are required, the large majority of the workflow is automated.
PastPerfect records and data can be exported in a variety of formats, including PastPerfect’s own flavor of XML. For the purposes of our project, we decided to export records in this PastPerfect-XML format, which meant that we would eventually be transforming one type of XML into another, i.e. PastPerfect-XML into EAD-XML. We decided that such a transformation would be easier and more straightforward than any other, as it only requires one transformation and one language.
The Workflow
Stylesheet Creation
Upon starting the project, I worked closely with Dmitri Rudnitsky, an Information Systems undergraduate student at UMBC skilled in computer programming. Dmitri and I learned as much about EAD, XML, and XSLT as we could in two weeks, then set to work on the most technical aspect of the project: the XSLT stylesheet. XSLT (Extensible Stylesheet Language Transformations) is a language that is used to transform one XML file into another XML file. Not to get too technical, but we used this language to write functions that would take data from the PastPerfect-XML and rewrite it in the form appropriate to EAD-XML. Since Dmitri had to leave at the end of April, we wanted to utilize his expertise on this part of the project prior to his departure. By the time he left the project, I hoped to have learned enough to carry on with the rest of the work myself.
Fortunately, we had a working version of the stylesheet by the time Dmitri left. By this time, I also felt comfortable tweaking, streamlining, and editing the stylesheet on my own as the work progressed and I learned more about XSLT. This stylesheet is available on the project's GitHub space: https://github.com/UMBC-Library/EAD-XML/blob/master/stylesheets/PPtoEAD_withComments.xsl. A few months later I was able to create two more stylesheets for the project: one that splits a batch file into individual files and one that transforms the EAD-XML into HTML for web display.
Data Cleanup
Once we completed the initial version of the stylesheet, I shifted gears and started focusing on the data export from PastPerfect. Before we could extract any data, we had to ensure that it was as standardized and error-free as possible. Using the descriptive rules outlined in the Society of American Archivists’ Describing Archives: A Content Standards (DACS), we developed our own set of guidelines and standard forms for each field in PastPerfect. We then checked and edited each field in each record to adhere to the guidelines and ensure a uniform output.
Occasionally, in order to correctly fill in a field, I had to physically locate a collection and identify or verify certain features. Most frequently this meant counting the number of boxes and calculating the equivalent linear footage, or checking to see what condition the collection was in and if it required conservation. Other times, it meant checking accession paperwork and describing how, when, or from whom we had acquired a collection.
Prioritization of Records
After the records were cleaned up, we prioritized all of them (about 150) into three groups: high, medium, and low. Prioritization was based on how complete they were or how much further editing they required. We added all of this information into a spreadsheet to track each record’s priority ranking, required edits, data cleanup status, and export status.
Export
Initially, we did not think we could process a batch PastPerfect-XML file, which is how PastPerfect exports data for multiple records. We knew we ultimately needed an individual EAD-XML file for each collection and thought that in order to achieve this we would need to export each record individually from PastPerfect then transform each record individually into EAD-XML. This would have been an extremely time consuming task due to the PastPerfect export interface and the transformation tool we were using.Fortunately, after much brainstorming, trial, and error, I was able to create a batch processing tool that not only transforms one PastPerfect-XML file into EAD-XML but also splits it into multiple files. The result is a folder of files: one EAD-XML finding aid per record. Once I had the batch tool working, I exported all records from PastPerfect classified as highest priority into a batch file.
Transformation and Post-Processing
After export, I ran the batch tool on the PastPerfect-XML batch file which contained records for 38 collections. After about one second, a folder appeared containing 38 EAD finding aids.
As discussed earlier, it was not possible (or within the scope of my expertise) to automate every aspect of the EAD creation. This meant that a few aspects of each EAD file needed some manual edits. Most notably, the source and classification of subject terms and people names had to be added (i.e. if it was a Library of Congress subject heading or a local term, if a subject was a geographic location or a genre, etc.). Samples of these records are available on Github.
HTML for Web Display
The final step was to make the now complete EAD finding aids displayable on the internet. This meant using another stylesheet to transform the EAD-XML into HTML. To do this, I ran all of the new EAD-XML files through another batch tool, resulting in 38 HTML files. I then created a cascading stylesheet (CSS) to style the HTML, ensuring consistency with the new UMBC Special Collections website. While not complete, the final product will be an individual webpage for each collection that displays EAD data in a readable way and also links to the raw XML file as well as a printable PDF version of the EAD finding aid. The current templates for both of these processes are available through Github. Here is an example of how the EAD finding aid might display online:
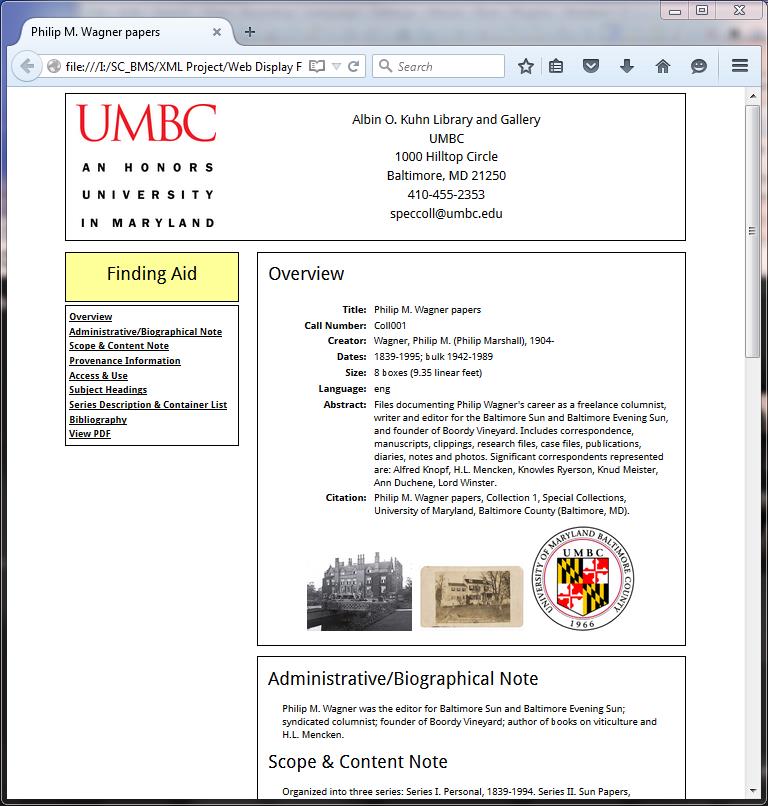
Thank you for this thorough description, Emily! Although Emily is leaving UMBC very soon, the EAD project will continue into 2016. Have questions? Contact Lindsey Loeper, Special Collections Archivist, at lindseyloeper@umbc.edu or 410-455-6290.





